(白式)IDS 延展语法导论
(2026-03-21 更新)
1. IDS 简介
IDS 是 Ideographic Description Sequences(表意文字描述序列)的缩写,用于描述汉字的结构,如「⿱次乙 」可描述汉字「乲」。虽然 IDS
的设计初衷是为了描述汉字的结构,但它的语法主旨是形容部件之间的相对位置而非笔画级差异,导致 IDS 的容错性较大,如「⿻丨日 」可同时表示「田」「甴」「由」「申」「甲」「曱」。
因此,字统网 (zi.tools) 站长白易 在 IDS的基础上延展了特殊语法形成了「白式 IDS」,以消除 IDS 的歧义。
使用该 IDS 语法表述的数据库在 https://github.com/yi-bai/ids 以 MIT 授权开源发布。本文尝试解说「白式 IDS」中的特殊语法。
2. Unicode IDS 语法
2.1. IDC 字符种类
截至 Unicode 16.0.0,共有17种 IDC(Ideographic Description Characters,即表意文字描述字符)。在。它们及其 Unicode 码点、含义和用例如下表所示:
IDC
U 码
字统快捷键
含义
用例
⿰
U+2FF0
LR (left right)
左右结构
从 ⿰人人
⿱
U+2FF1
UD (up down)
上下结构
仌 ⿱人人
⿲
U+2FF2
LL (left left)
左中右结构
衍 ⿲彳氵亍
⿳
U+2FF3
UU (up up)
上中下结构
佥 ⿳亼𭕄一
⿴
U+2FF4
OC (over center)
全包围结构
囚 ⿴囗人
⿵
U+2FF5
OD (over down)
上包围结构
冈 ⿵冂乂
⿶
U+2FF6
OU (over up)
下包围结构
凶 ⿶凵乂
⿷
U+2FF7
OR (over left)
左包围结构
区 ⿷匚乂
⿸
U+2FF8
RD (right down)
左上包围结构
仄 ⿸厂人
⿹
U+2FF9
LD (left down)
右上包围结构
寸 ⿹𬺰丶
⿺
U+2FFA
RU (right up)
左下包围结构
亾 ⿺𠃊人
⿻
U+2FFB
XX (交叉)
重叠
巫 ⿻工从
⿼
U+2FFC
OL (over left)
右包围结构
㕚 ⿼叉丶
⿽
U+2FFD
LU (left up)
右下包围结构
斗 ⿽十⺀
⿾
U+2FFE
MI (mirror)
水平镜像
𱤻 ⿾止
⿿
U+2FFF
RO (rotate)
旋转
𠄔 ⿿予
㇯
U+31EF
SU (subtract)
删减
丅 ㇯下丶
注:U+31EF 较为特殊,因为它不在表意描述字符区段中,可能是由于该区段已无空位。
EBNF 语法定义:
IDS_Sequence ::= ...
| IDS_UnaryOperator IDS_Component
| IDS_BinaryOperator IDS_Component IDS_Component
| ...
| IDS_TrinaryOperator IDS_Component IDS_Component IDS_Component
IDS_UnaryOperator ::= [⿾⿿]
IDS_BinaryOperator ::= IDS_BinaryUnique | IDS_BinaryOverlap | IDS_BinaryAmbiguousWrapping
IDS_BinaryUniqueOperator ::= [⿰⿱⿸⿹⿺⿽]
IDS_BinaryOverlapOperator ::= "⿻"
IDS_BinaryAmbiguousOperator ::= [⿴⿵⿶⿷⿼㇯]
IDS_TrinaryOperator ::= [⿲⿳]2.2. 无嵌套的 IDS 语法
无嵌套的 IDS 语法十分简单,为:<IDC><TAB><汉字 ...> 。例:
苒 ⿱艹冉 万 ⿱一勹 丕 ⿱不一 丬 ⿰冫丨 中 ⿻丨口 以 ⿲𠄌丶人 𱤻 ⿾止
2.3. 有嵌套的 IDS 语法
IDS 允许无限嵌套,例:
⿰⿱⿰先先 貝攵
↓
⿰⿱ 貝 攵
↓
⿰ 攵
↓
𣀹
「𣀹」的 IDS 嵌套结构示例
其他嵌套结果例子:
𣀱 = ⿰⿳米丗⿻人⿱艹一攵
𣀎 = ⿰⿳爫出⿺𠃊小攴
其他 IDS 嵌套结构示例
3. 白式 IDS 语法
3.1. 前言
以下章节将表述由字统网站长白易自定义的 IDS 语法,如:「{曰}⿴囗一 」只表示「曰」,而不能表示「日」;「⿻[:-1]丨日 」只表示「由」,而不能表示「甲」「申」「甴」「曱」……所有以下提到的语法皆可以在 字统网上的「组字」tab 使用。另外,上面 §2.1〈IDC 字符种类〉 中的「字统快捷键」表格栏也可在该页面使用。
本文接下来于内文使用的定义语法为:<字> <TAB> <IDS 定义组>,中间 TAB 字符为 U+0009 字符,表示 <字> 的 IDS 定义为 <IDS 定义组>。如果一个字有多个 IDS 定义,则可以使用第二个 TAB 字符分隔开来,如:<字> <TAB> <IDS 定义组> <TAB> <IDS 另类定义组>,其中 <IDS 定义组> 是默认拆分的方式,<IDS 另类定义组> (alternative) 则是拆分成比较不合理、不常见的部件。例如「滟」的 IDS 条目:
滟 ⿰氵.艳. ⿰沣.色.
一般应拆成「⿰氵艳 」,而不是另类组的「⿰沣色 」)。
EBNF 语法定义:
IDS_Definition_Row ::= Ideograph_Char TAB IDS_Locale_Definition (TAB IDS_Alternative_Definition)
IDS_Locale_Definition ::= IDS_Sequence | IDS_Locale_Sequence (";" IDS_Locale_Sequence)*
IDS_Alternative_Definition ::= (IDS_Sequence | IDS_Locale_Sequence) (";" (IDS_Sequence | IDS_Locale_Sequence))*
3.2. 特殊符号
为方便在字统网上快速搜索汉字,字统网特别添加了一个特殊 IDS 符号「🔄︎」(emoji: 🔄️ ,U+1F504)来表示「替换」。其用法为「🔄︎字₁字₂字₃ 」表示字₁里面的字₂部件换成字₃部件,如「嬴 🔄赢贝女 」表示将「嬴」里面的「贝」换成「女」。此 IDS 字符主要用于快速在字统网里面查询汉字,但不在字统网 IDS 数据库内使用。
字统网「替换」 IDS 符号示例
3.3. 数据库格式
本文研究的数据来源是字统网站长白易在 GitHub 上开源的 IDS 数据库 。以下所有延展语法的解说都是从该数据库的 IDS 定义提取出来。该数据库为每个汉字提供 IDS 定义,其中统一化的程度可区分为三级:
ids_lv0.txt:笔画级区分,例如一(横)和㇀(提)、丶(点)和㇏(捺)皆区分。
ids_lv1.txt:合并笔画级区分。
ids_lv2.txt:依据 Unicode UCV 表合并部件。
文件每行的格式参考 §3.1〈白式 IDS 语法前言〉 。
本文使用的UCV 表(Unifiable Component Variations, 可统一组件变体列表) 是 IRG (Ideographic Research Group,即「表意文字研究小组」)下 IWDS 系列二文件(IRG Working Document Series 2) 的最新文件。
以下内容皆以 lv0 IDS(即笔画级区分)为基础进行解说,提到的扩展语法都是 lv0 IDS 内已使用的语法。
3.4. 特殊语法分类
为方便理解,以下拆分不同章节分别解说:
汉字的字形变体:单个汉字如何记录不同变体;
笔画之间的相接:「笔画链」的概念和使用;
部件之间的重叠穿插:定义重叠和包围 IDS 符号;
唯一化及统一化:IDS 数据库里面 IDS 组合对应汉字变体的唯一化和统一化处理。
每章节都附带相关的 EBNF 语法定义和白式 IDS 数据库条目示例。
4. 汉字的字形变体
4.1. 概念
如果你细心观察 §2.3〈有嵌套的 IDS 语法〉 中「⿰⿱⿰先先貝攵 」的例子的话,你会发现直接接用此 IDS 组出来的字与实际上的「𣀹」有所不同:直接接用此 IDS
组出来的字的左上角的「先」的最后一笔是「乚」,但是「𣀹」的左上角的「先」的最后一笔是「𠄌」,这是由于部件避让的习惯而产生的差异。汉字有诸多写法,为了方便表示不同写法变体之间的其中一种,因此需要标上「字形变体标识符」(EBNF 语法内的 Variant_Identifier_Definition)。
4.2. 定义及使用语法
EBNF 语法定义:
/* 定义 IDS 组合里面的「字形变体标识符」 */
IDS_Locale_Sequence ::= ... IDS_Sequence Variant_Identifier_Definition?
Variant_Identifier_Definition ::= "(" Variant_Identifier ("," Variant_Identifier)* ")"
/* 在 IDS 里使用「字形变体标识符」 */
Ideo_with_Variant_ID ::= Ideograph_Char_with_Variant Variant_Identifier?
从 ids_lv0.txt 读取「令」(U+4EE4) 的条目是:
令 ⿱亽龴.(.);⿱亼.龴.(H);⿱人.𪜁(J);⿳人d丶.龴.(d..);⿱亼d龴.(dh.);⿱人d𪜁(dhs);⿱亽卩(hdx);⿱亼.卩(hsx) ⿱亼.𰆊(J);⿱亼d𰆊(dhs)
其中有两个 TAB 字符,依据 §3.1〈白式 IDS 语法前言〉 的说明可知有两段:「定义组」 ⿱亽龴.(.);⿱亼.龴.(H);⿱人.𪜁(J);⿳人d丶.龴.(d..);⿱亼d龴.(dh.);⿱人d𪜁(dhs);⿱亽卩(hdx);⿱亼.卩(hsx) 及 「另类定义组」 ⿱亼.𰆊(J);⿱亼d𰆊(dhs) 。其中每段变体的 IDS 之间以 ; 分隔,且每段变体后面以括号 () 包裹「字形变体标识符」。以下表格展示拆分以上 IDS 条目后得到的变体列表及代表字形。
字形变体标识符 ID
IDS 组别
IDS
变体来源
字形展示
(.)
定义组
⿱亽龴. G
令
(H)
定义组
⿱亼.龴. H,T (V,KP)
(J)
定义组
⿱人.𪜁 J,K
另类定义组
⿱亼.𰆊
(d..)
定义组
⿳人d丶.龴. G左边,上面人避点
領 左边
(dh.)
定义组
⿱亼d龴. H,T左边,上面人避点
領 左边
(dhs)
定义组
⿱人d𪜁 J,K左边,上面人避点
領 左边
另类定义组
⿱亼d𰆊
(hdx)
定义组
⿱亽卩
(hsx)
定义组
⿱亼.卩
「令」(U+4EE4)在白式 IDS 里面的字形变体列表
通过以上表格能看出,白式 IDS 里「令」一共有八种变体。如果要使用以上的变体,在其他使用「令」的汉字时,在「令」后面加上「字形变体标识符」即可。以下抽取两个使用「令」的汉字:「冷」及「刢」,并组装出它们的字形变体列表:
冷 ⿰冫令.(.);⿰冫令H(H);⿰冫令J(J)
字形变体标识符 ID
IDS 组别
IDS
使用的「令」变体
字形展示
(.)
定义组
⿰冫令. 令.(G)
冷
(H)
⿰冫令H 令H(H,T)
冷
(J)
⿰冫令J 令J(J,K)
「冷」(U+51B7)在白式 IDS 里面的字形变体列表
刢 ⿰令d..刂(.);⿰令dhs刂(J);⿰令dh.刂(T)
字形变体标识符 ID
IDS 组别
IDS
使用的「令」变体
字形展示
(.)
定义组
⿰令d..刂 令d..(G左边,上面人避点)
刢
(J)
⿰令dhs刂 令dhs(J,K左边,上面人避点)
(T)
⿰令dh.刂 令dh.(H,T左边,上面人避点)
「刢」(U+5222)在白式 IDS 里面的字形变体列表
由此可见,通过使用不同的字形变体标识符,可以在不同的应用场景中灵活地选择任意汉字的字形,只要该汉字有相对应的字形变体。
注:如果汉字本身没有对应的字形变体,则可以省略 字形变体标识符。
4.3. 字形变体标识符的种类
字形变体标识符的种类较多,大致可以分为以下四种。
EBNF 语法定义:
Variant_Identifier ::= Wildcard_Source | Unicode_Sources | UCV_Full_Position | Imaginary_UCV | Alternate_Variants4.3.1. 提交源的变体
EBNF 语法定义:
Wildcard_Source ::= "."
Unicode_Sources ::= [BGHJKMPSTUVQ]
每个汉字都有一个及以上的提交源,每个提交源的字形都可能不一样。针对提交源的变体,「字形变体标识符」使用的是各个提交源的大写字母。各个提交源的「字形变体标识符」字母如下:
字形变体标识符 ID
提交源
来源
B
UK
英国
G
G
中国大陆(仅用于不符合「抽象构型」的「彐(U+5F50) 」)
H
H
香港
J
J
日本
K
K
韩国
M
M
澳门
P
KP
朝鲜
S
SAT
大藏经文本数据库委员会
T
T
台湾
U
UTC
美国及 Unicode 技术委员会
V
V
越南
Q
UCS2003
UTN #53 ,Unicode 13.0 以前的 UCS2003 栏
.
通配符
取符合「抽象构型」的所有提交源,默认包括 G 源(除上述特例)
如有多个源字形的 IDS 组合一致时,提交源「字形变体标识符」按 Unicode 码表内最先出现的源标识符为代表符。目前 Unicode 码表顺序为:
Q > G > H > T > J > K > P > V > M > U > S > B
提交源变体示例:
伨 ⿰亻匀.(.) ;⿰亻勻(H)
↓
伨
(.)
;
伨
(H)
𣂀 ⿰⿸厂.兆t斗(.) ;⿰𠩓斗(Q)
↓
𣂀
(.)
;
(Q)
睹 ⿰目者.(.) ;⿰目者K(J)
↓
睹 ⿰目者(.) ;⿰目者(J)
↓
睹
(.)
;
睹
(J)
4.3.2. UCV 规则下的变体
EBNF 语法定义:
UCV_Full_Position ::= [qpxy] UCV_ID_Number UCV_Position_Number
UCV_ID_Number ::= Three_Digit_Number [a-z]?
UCV_Position_Number ::= (Positive_Numeral | Two_Digit_Number) [xy]?
Imaginary_UCV ::= "qq" UCV_ID_Number+
如果一个 IDS 组成的某些部件使用了某个 UCV 规则(下文称为「UCV」)下的其他变体,则该 IDS 组合的「字形变体标识符」就以 q (或p - 撇、x - 交叉、y - 其他)开头,后面接上该 UCV 的三位数序号(若序号的数字不足,用 0 补足),再接上该 UCV 中的某个字形的索引(若该 UCV 少过 10 个变体,索引为一位数从 1 开始,否则索引为二位数从 01 开始),最后还可以接上一个小写字母 x 或 y 表示其他异体。
例一:「烕 ⿵戌大.(q008a2) 」中的「(q008a2)」表示该 IDS 适用于 UCV #8a 的第二个字形(如下图)。
UCV #8a
例二:「龰 ⿱丷乀.(q3932) 」中的「(q3932)」表示该 IDS 适用于 UCV #393 的第二个字形(为一位数)。
UCV #393
例三:「滿 ⿰氵.⿱艹.⿵𠔼十.(q454a17) 」中的「(q454a17)」表示该 IDS 适用于 UCV #454a 的第十七个字形(如下图)。
UCV #454a
当一个字通过类推/反推 某个 UCV 的部件而创造出新的变体 ,则该 IDS 组合的「字形变体标识符」就以 qq开头,后面接上一个或多个 UCV 的三位数序号(若序号的数字不足,用 0 补足)。
例一:「父 ⿱八d乂.(.); ⿱儿.乂.(qq222) 」中的「(qq222)」表示该 IDS 描述 ⿱儿.乂. 中相对于 (.) 有一个部件(八d)变成了 UCV #222 中的一个变体(儿.)。见下两图。
UCV #222
⿱八d乂.(.) ; ⿱儿.乂.(qq222)
↓
⿱乂(.) ; ⿱儿乂(qq222)
↓
父(.) ; (qq222)
依据 UCV #222 生成的 qq222 变体
例二:「 ⿱夂.月.(.); ⿱攵.⺼.(qq053194) 」(U+21559) 中的「(qq053194)」表示该 IDS 描述 ⿱攵.⺼. 的字中有一个部件(月)变成了 UCV #53 中的一个变体(⺼),还有一个部件(夂)变成了 UCV #194 中的一个变体(攵)。见下两图。
UCV #53 & UCV #194
⿱夂.月.(.) ; ⿱攵.⺼.(qq053194)
↓
(.) ;(qq053194)
依据 UCV #53 & UCV #194 生成的 qq053194 变体
4.3.3. 笔画样式及位置差异的变体
EBNF 语法定义:
Alternate_Variants ::= [0-9a-z.]+
如果一个字存在笔画级别差异或部分部件的位置差异的变体,则该 IDS 组合的「字形变体标识符」就会以小写字母、点 . 及数字标示。
笔画样式及位置差异的示例:
丰 ⿻丿三(..p)
↓
(..p)
然后
邦 ⿰丰..p 阝(.)
↓
邦 ⿰ 阝
勳 ⿺熏力(r)
↓
(r)
刍 ⿱⺈⺕(x)
↓
(x)
务 ⿱攵力(y)
↓
(y)
常见的笔画式「字形变体标识符」字符及其含义如下:
.:占位符、默认字形a:未知b:未知c:未知d:点g:钩h:横n:捺p:撇s:竖t:提w:弯x:更多交叉(x 为 cross 的缩写)y:更少交叉z:折
常见的位置「字形变体标识符」字符及其含义如下:
u:上(up)l:左(left)r:右(right)
「字形变体标识符」的完整组合是对该字的全部部件,每个部件的笔画样式字符或使用的「字形变体标识符」,按部件顺序串联,例:上文中的「(..p) 」表示「丰」的前两个部分不改变,而第三个部分中的一部分与撇相似的笔画变成撇,即代表「」;「(r) 」表示「勳」的某个部分(灬)往右移动一些,于是「勳」就变成了「」。
此类「字形变体标识符」一般用于表示某个汉字应该用的是部件的原字形,但是由于某些因素(避让)需要更换成不同的字形。例如:「子」有两个 IDS「字形变体标识符」:⿻了.一.(.) 和 ⿻了.一t(t) ,这表示即使子t (「孩」左)中间看起来是一个提#(T) ,但是实际上是由「一」避让而来的一t ;「孑」就不一样,其 IDS ⿻了.㇀ 直接表明中间的部件是不同的,是「㇀ 」(提)而不能写成横。此类「字形变体标识符」在§7.2 〈lv1 的合并〉 将有妙用。
4.3.4. 其他变体
EBNF 语法定义与 §4.3.3 〈笔画样式及位置差异的变体〉 一样,「字形变体标识符」使用小写字母、点 . 及数字标示。部分常见变体如下:
「(m)」表示镜像汉字或带有镜像部件的变体,例:「𱤻 ⿾ 止.(m) 」「𡴧 ⿳屮.⿰止.𱤻m 亡.(m) 」
「(e)」表示该 IDS 组合出的字与原字相似(?)但不在 UCV 规则内,例:「𠪧 ⿰𠂬果.(e) 」
以「j」「q」或数字开头表示其他种类的笔画差异,例:「(jss) 」「(qy) 」「(2t) 」……
𠁁 ⿱⿰⿸#(丿𠃊)#(丨-一𠃑)#(一-𠃍𠃑-一丨)一.(y2)
↓
(y2)
「𠁁(U+20041)」 的 y2 类变体
4.3.5. 注释
实际上,§4.3.2 〈UCV 规则下的变体〉 、§4.3.3 〈笔画样式及位置差异的变体〉 、§4.3.4 〈其他变体〉 都是「字形变体标识符」的自定义 子类,使用小写字母、数字和点 . 组合而成。它们之间并没有严格的界限,某些变体可能同时属于多个上述子类。只要「字形变体标识符」的语法符合上述 EBNF 定义,并且能够清晰地区分某个汉字内不同字形变体的不同 IDS 组合,就是合法的「字形变体标识符」。
5. 笔画之间的相接
5.1. 笔画链的简介
有些字中有一些结构难以用一般 IDS 描述,或只能以自循环表述,如「乙」「亞」「凸」「一」……为了仍可描述这些汉字的写法而不陷入自循环,就有了「笔画链」(EBNF 语法内的 Stroke_Chain)。
5.2. 笔画链语法
EBNF 语法定义:
IDS_Sequence ::= Stroke_Chain | ...
Stroke_Chain ::= "#" "(" Stroke_Part+ "z"? ")"
「笔画链」以 #( 开头,以 ) 结尾,中间部分包含笔画字符、控制字符和笔画修饰字符。笔画字符和笔画修饰字符也可用字母代替以避免自循环和方便输入。笔画字符又可分为独立笔画字符和复合笔画字符。「笔画链」里的笔画字符按顺序首尾相连 ,连贯地书写下去,所以称之为「链」。所有笔画忽略书写时的角度,只关注笔画的起点、终点和粗细变化。「笔画链」作为一个独体,当与其他部件穿插重叠时,仍然保持「笔画链」的笔画顺序和连接关系不变。
5.3. 独立笔画字母
EBNF 语法定义:
Stroke_Part ::= StReversed_Indicator? (Ideograph_Char | Stroke_Letter) (StCrossing_Indicator | StBreak_Indicator)?
Stroke_Letter ::= [HSPN] [g]? | [SP] "Hw" [g]? | [DTJZ] | "Wg" | [Q][abcd]
StReversed_Indicator ::= "-"
StCrossing_Indicator ::= "x" Number
StBreak_Indicator ::= "b"
笔画字母示例
独立笔画字母包括:
一:H 横
丨:S 竖
丿:P 撇
乀:N 捺
丶:D 点
㇀:T 横折
㇝:J 提捺
←:Z 左(仅用于㇘ #(SZ) 兼容《康熙字典》形)
㇁:Wg 弯钩(W不会单独出现,必须是 Wg)
◝:Qa
◞:Qb
◟:Qc
◜:Qd
注:Q(圈)系曲线的书写方式依据顺时针。
笔画修饰字符包括:
w:只能在 SH 或 PH 之后使用,表示横的起始连接处更圆润,如:㇄ #(SHw ) 。注意不要将其与笔画字符「W」混淆。g:表示这个笔画的末尾带钩,如:㇁ #(Wg ) 。只能在 H、S、P、N、W 之后使用;其也可与「w」连用,此时置于「w」之后,如:㇈ #(HSHwg)。 b:用于单个笔画字符之后,表示笔画强制中断,标准化时不可连接下一笔变成另一个笔画;但是下一笔起始点仍在当前笔画的末端位置。如凵y:凵 #(丨b 一-丨)(y) ,用于廿 ⿻凵y 一. 表示「廿」的「凵」应当拆成三笔。
控制字符包括:
-:用于单个笔画字符之前,表示这个笔画字符的组合方向方向要倒着写(指起点和终点反转),如:𠃎 #(一-丨 ) 在组合时里面的「丨」的终点。z:用于单个笔画链的末尾,表示这个笔画链首尾相连,如:口 #(-丨𠃍-一z ) 。
x:用于单个笔画字符之后,在此控制字符之后要加上一个正整数 n,表示这个笔画字符与其所在笔画链中的第 n 个笔画字符交叉(笔画字符的序号是从 0 开始数,而不是从 1 开始)。取 IDS 条目母 ⿻⿴#(-𠃌𠃊x0 )⺀一 为例,「母」外框「」的笔画链如下:
其他 x 例子:
又 #(-乀x1㇇)
𡆢 ⿴囗#(◞0 x3 ◟1 ◜2 ◝3 -◟4 )
𠇇 ⿰亻⿺⿻#(丨x3◞◟◜) 二丶 𠍋 ⿲亻⿱丶#(㇇◝x4◞◟◜) 𧈧
下表提供复合笔画字符和部分汉字的「笔画链」:
复合笔画字符
⺄
㇁
㇂
㇄
㇅
㇇
㇈
笔画链
#(HNg)
#(Wg)
#(Ng)
#(SHw)
#(HSH)
#(HP)
#(HSHwg)
复合笔画字符
㇉
㇊
㇋
㇌
㇍
㇎
乁
笔画链
#(SHSg)
#(HST)
#(HSHP)
#(HPWg)
#(HSHw)
#(HSHS)
#(HN)
复合笔画字符
㇝
㇢
乙
乚
乛
亅
𠃊
笔画链
#(J)
#(Pg)
#(HPHwg)
#(SHwg)
#(Hg)
#(Sg)
#(SH)
复合笔画字符
𠃋
𠃌
𠃍
𠃑
𠄌
𠄎
〇
笔画链
#(PH)
#(HSg)
#(HS)
#(SHS)
#(ST)
#(HSHSg)
#(◟◜◝◞z)
汉字
𠂆
匚
𠤬
𱍫
弓
己
巳
笔画链
#(丿丿)
#(-一𠃊)
#(-𠃊㇈)
#(-𠃊㇎z)
#(𠃍-一㇉)
#(𠃍-一乚)
#(一-𠃍乚)
笔画链的示例:
兜 ⿱⿲#(丿𠄌) 白コ儿.(.)
↓
兜 ⿱⿲ 白コ儿.(.)
乌 ⿱丿⿹#(-𠃌㇉) 一.(.)
↓
乌 ⿱丿⿹ 一.(.)
母 ⿻⿴#(-𠃌𠃊x0) ⺀一.
↓
母 ⿻⿴ ⺀一.
𠆭 ⿳人.二.#(丨x4◞◟◜◝◞◝◞◝) (.)
↓
𠆭 ⿳人.二. (.)
6. 部件之间的重叠穿插
6.1. 重叠标记的简介及基础概念
重叠 IDC (⿻ , U+2FFB)有时会具有歧义,如「⿻丨日 」除能表示「甲」外,还可以表示「申」「曱」「甴」「由」「田」。重叠标记语法设计来解决此问题,尽可能表示笔画之间的穿插关系,例如将「甲」的 IDS 限制为「⿻[1:]丨日 」。
在白式 IDS 语法中,重叠 IDC (⿻字₁字₂ )的语法被添加了限制。⿻字₁字₂ 中,字₁ 是纵向部件 ,字₂ 是横向部件 。纵向部件代表汉字里面的「竖」或接近的垂直结构,例如:「艹」「〢」的两竖、「口」的左竖和【横折中的竖】、竖撇「丿」);横向部件代表汉字里面的「横」或接近的水平结构,例如:「口」的【横折中的横】和下面的横、「コ」的【横折中的横】和下面的横、「乐」的第一笔撇与第二笔【竖折中的横】。
白式 IDS 语法中,重叠 IDC 添加了扩展语法「穿过表达式 」(EBNF 的 Overlap_Modifier)以对重叠 IDC 提供更多资讯。扩展语法为在重叠 IDC 后面添加方括号[ ],里面添加描述字符,即变成⿻[...]字₁字₂ 。重叠 IDC 的扩展语法目前有两种版本:速成版和完整版,另外还有一个特例。
EBNF 语法定义:
IDS_Sequence ::= ... | IDS_BinaryOverlapOperator Overlap_Modifier IDS_Component IDS_Component | ...
Overlap_Modifier ::= "[" Overlap_Matrix ("|" Overlap_Matrix)? "]"
IDS_BinaryOverlapOperator ::= "⿻"6.2. 重叠速成版:垂直结构穿过水平结构的限制语法
EBNF 语法定义:
Overlap_Matrix ::= Overlap_Horizontal_Indexing | ...
Overlap_Horizontal_Indexing ::= (Number | Negative_Number)? ":" (Number | Negative_Number)?
垂直结构穿过水平结构的限制语法,在「穿过表达式」里为:前面一个正整数,后面一个(一般是负)整数,中间用冒号分隔。两个整数中可省略其中一者,但不能都省略。
「申」里带「虚拟」横的水平结构序号示例
6.2.1. 普通情况
最常见的限制语法是:⿻[a:b]字₁字₂ (a、b 为正整数)表示 字₁ 里面的全部 垂直结构的顶端在 字₂ 的第 a 个水平结构正下面接触 (如「丅」形);字₁ 垂直结构的底端在 字₂ 的第 b 个水平结构正上面接触 (如「丄」形)。字₂ 的水平结构的序号从 1 开始、从上往下数;如果是负数,则从下往上数,-1 表示最后一个水平结构。
6.2.2. 负数情况
如果 ⿻[a:b]字₁字₂ 里 b 前面带有负号(如⿻[a:-y]字₁字₂ ),则表示 字₁ 垂直结构的底端在 字₂ 的倒数 (从下往上数)第 y 个水平结构接触而非正数;如果 a 前面带有负号(如⿻[-x:b]字₁字₂ )同理。
冒号 : 前面的数字应当取尽量取正数 a,除非倒数时 -x 的 x 比正数时的 a 小(如数值 -1);冒号 : 后面的数字应当尽量取负数 -y,除非正数时的值 b 比 y 小(如数值 1)。
6.2.3. 省略情况
若省略冒号 : 前面的数字(如 ⿻[:b]字₁字₂ ),则表示 字₁ 垂直结构的顶端往上凸出 字₂ 的第一个水平结构之上(垂直结构底端遵循 b);其可视为触碰第 a = 0 个水平结构(即第一个水平结构再上面的一个「虚拟」横)。
若省略冒号 : 后面的数字(如 ⿻[a:]字₁字₂ ),则表示 字₁ 的底端往下凸出 字₂ 的最后一个水平结构之下(垂直结构顶端遵循 a);其可视为触碰第 b = -0 个水平结构(即最后一个水平结构再下面的一个「虚拟」横)。
若是直接省略方括号⿻字₁字₂ (即默认情况)即代表垂直结构的顶端和底端都在水平结构的范围之外(即上下都凸出);不要写成⿻[0:-0]字₁字₂ 或⿻[:]字₁字₂ 。可参考上图「申」计算⿻丨日 里的水平结构序号。
6.2.4. 例子
下面以最经典的重叠 IDS「⿻丨日 」为例来说明重叠速成版的限制语法。字₁ 的垂直结构就是「丨」,字₂ 的水平结构是「日」里面的三个横。以下就以重叠 IDS + 限制语法分开展示⿻丨日 如何可以组合成「甴」「由」「申」「甲」「曱」「田」。
汉字
正式重叠 IDS 限制语法
等价但错误的写法
甴
⿻[:-2] 丨日
⿻[:2] 丨日
由
⿻[:-1] 丨日
⿻[:3] 丨日
申
⿻丨日
⿻[:] 丨日
⿻[0:-0] 丨日
甲
⿻[1:] 丨日
⿻[-3:] 丨日
曱
⿻[2:] 丨日
⿻[-2:] 丨日
田
⿴囗十
(你以为会很复杂?)
⿻[1:-1] 丨日
⿻[1:3] 丨日
⿻[-3:-1] 丨日
⿻[-3:3] 丨日
重叠 IDS「⿻丨日 」使用重叠速成版语法区分不同汉字
6.3. 重叠完整版:任意穿插的矩阵结构
EBNF 语法定义:
Overlap_Matrix ::= ... | Overlap_Rows | Overlap_Cell+
Overlap_Rows ::= Overlap_Row? ("," Overlap_Row?)+
Overlap_Row ::= Overlap_Cell*
Overlap_Cell ::= Overlap_Identity | Overlap_Crossing | Overlap_Non_Crossing
Overlap_Identity ::= "." | "_"
Overlap_Crossing ::= [xabcd]
Overlap_Non_Crossing ::= [lr]
汉字最基础笔画结构是「横」和「竖」。笔画穿插(大多数情况下)是由「横」和「竖」之间的穿插关系引起的,因此重叠标记的设计主要考量「横」和「竖」之间的关系,而纵横交叉最自然的方式就是矩阵结构。重叠完整版的矩阵字串表示重叠 IDC 中「横」和「竖」之间的穿插关系,甚至可以表示更复杂的穿插关系(如「丅」「丄」「⺊」「┤」形)。
以下步骤描述如何分析重叠 IDC 中的矩阵穿插关系:
计算 字₁ 纵向部件内的垂直结构数量,得 n 竖
计算 字₂ 横向部件内的水平结构数量,得 m 横
准备一个 m 横行 × n 竖列大小的穿过矩阵。
for 横i in 1..m(字₂ 里的横,上到下):
竖j in 1..n(字₁ 里的竖,左到右):
如果字₁ 的第竖j 与字₂ 的第横i 交叉(十形):
字₁ 竖j 有多个垂直段?有的话,从上到下依序每段打 a 、b 、c ...注1 横i竖j 元素为交叉对应垂直段的字母字₁ 竖j 没有多个垂直段,矩阵的横i竖j 元素元素为 x
否则如果字₁ 的第竖j 顶在字₂ 的第横i 上(丅形或丄形,可以不触碰),则矩阵横i竖j 元素为 .
否则如果字₂ 的第横i 顶在字₁ 的第竖j 上(⺊形或┤形,可以不触碰),则矩阵横i竖j 元素为 _
分析完所有横i 和竖j 后,得到一个完整填充的穿过矩阵表示。
为每一行进行简化:
如果一行均为 x 或 a 的任意组合,可留空该行。
如果一行均为 . ,可以用一个元素代替
如果一行(横i)均为 _ :
如果横i 在所有竖的左边(-|||…| 形),则矩阵的横i行全部替换为一个 l 元素
如果横i 在所有竖的右边(|…|||- 形),则矩阵的横i行全部替换为一个 r 元素
然后再为整体穿过矩阵进行简化:
如果第 m 行到第 n 行之间(不含头尾)均为 x ,其他行均为 . ,则视为 §6.2〈重叠速成版:垂直结构穿过水平结构的限制语法〉 可简化成 m:n(m、n 为负数时表示到最后虚拟 -0 行的距离)。m、n 为 0 时应省略注2
如果矩阵里面全部元素是 x (全部穿过)、或只有一行一列且是元素 a (⿻[a] ),应直接不写「穿过表达式」(即默认情况)。
将简化后的穿过矩阵,每行的元素直接连写,行和行之间用逗号 , 连接,形成「矩阵字串」。
「矩阵字串」使用方括号 [ ] 包裹,形成最终的「穿过表达式」。
注1 :步骤4.a.i 「
字₁ 竖j 有多个垂直段?有的话,从上到下依序每段打
a 、
b 、
c ...」,可以参考下图
⿻㇉一 :垂直部件 「
㇉ 」有两个垂直段,上面的竖是
a ,下面的竖勾是
b 。
其中
⿻[a]字₁字₂ 和
⿻[x]字₁字₂ 一样属于默认情况不写「穿过表达式」,
⿻[a]㇉一 应该简化成
⿻㇉一 。类推可知 「
弓 」有三个垂直段,分别是
a 、
b 、
c 。
注2 :实际上横向部件计数的限制语法参考
Python 的切片语法 ;水平结构的计数方式从上到下,0 为第一横:
,而不是
§6.2〈重叠速成版:垂直结构穿过水平结构的限制语法〉 说的「从 1 开始」。
在此情况下,切片语法
m:n 代表第
m 行到第
n - 1 行之间均为
x ,其他行(包括
n)均为
. 。穿过矩阵里面,第
m 行(到第
n - 1 行)的元素是
x,第
n 行的元素是
.。
例:
[.0 , .1 , .2 , x3 , x4 , x5 ] 中从第 3 行到第 5 行均为
x ,其他行均为
. ,因此可以简化成
[3:](最后一行出头)或错误的
[3:6]/
[3:-0](
6/
-0 表示该行不是
x,但是第 6 行并不存在而错误) 。
另外提供
§6.2.4 的切片语法和穿过矩阵对比。
汉字
切片语法
穿过矩阵
甴
⿻[:-2] 丨日
⿻[x, .-2 , .-1 ] 丨日
由
⿻[:-1] 丨日
⿻[x, x, .-1 ] 丨日
申
⿻[:] 丨日
⿻[x, x, x] 丨日
甲
⿻[1:] 丨日
⿻[.0 , x1 , x] 丨日
曱
⿻[2:] 丨日
⿻[.0 , .1 , x2 ] 丨日
田
⿻[1:-1] 丨日
⿻[.0 , x1 , .-1 ] 丨日
重叠 IDS「⿻丨日 」在不同汉字中的「切片语法」和「穿过矩阵」的对比
为什么
§6.2〈重叠速成版:垂直结构穿过水平结构的限制语法〉 会说「从 1 开始」呢?这是因为 Python 的切片语法的
a:b 是包括
a 但不包括
b 的区间,导致「从 0 开始」数的
a 对应的符号是
x(交叉),但是
b 对应的符号是
.(正上/下方),需要记忆「
a 横是第一个横竖交叉点,
b 横最后触碰竖」。如果简单的介绍用「从 1 开始」数,则
a 和
b 都对应的符号是
.,更容易理解成「
a 横和
b 横都触碰竖」,这就需要引入「虚拟」横的概念且能够对应反向的
-0 横。
例:「曲 」如果拆分成「⿻〢日 」,则「〢 」是纵向部件,「日 」是横向部件。按以上步骤开始分析「曲 」的穿插关系以得到「⿻[:-1]〢日 」:
「曲 」的穿插关系分析(展开阅读)
字₁ 纵向部件「〢 」内的垂直结构数量,n = 2字₂ 横向部件「日 」内的水平结构数量,m = 3矩阵 = 3 行 × 2 列,表示为 [(?,?), (?,?), (?,?)]
日 里的横₁:
〢 里的竖₁:
如果 字₁ 的第竖₁ 与字₂ 的第横₁ 交叉(十形),则矩阵的横₁竖₁元素为:x (竖₁ 没有多个部分)
〢 里的竖₂:
如果 字₁ 的第竖₂ 与字₂ 的第横₁ 交叉(十形),则矩阵的横₁竖₂元素为:x (竖₂ 没有多个部分)
// 此时矩阵 = [(x,x), (?,?), (?,?)]
日 里的横₂:
〢 里的竖₁:
如果 字₁ 的第竖₁ 与字₂ 的第横₂ 交叉(十形),则矩阵的横₂竖₁元素为:x (竖₁ 没有多个部分)
〢 里的竖₂:
如果 字₁ 的第竖₂ 与字₂ 的第横₂ 交叉(十形),则矩阵的横₂竖₂元素为:x (竖₂ 没有多个部分)
// 此时矩阵 = [(x,x), (x,x), (?,?)]
日 里的横₃:
〢 里的竖₁:
如果 字₁ 的第竖₁ 与字₂ 的第横₂ 交叉(十形):(条件不符合)
如果 字₁ 的第竖₁ 顶在字₂ 的第横₃ 上(丅形或丄形),则矩阵的横₃竖₁元素为:.
〢 里的竖₂:
如果 字₁ 的第竖₂ 与字₂ 的第横₂ 交叉(十形):(条件不符合)
如果 字₁ 的第竖₂ 顶在字₂ 的第横₃ 上(丅形或丄形),则矩阵的横₃竖₂元素为:.
分析完所有横i 和竖j 后,完整的穿过矩阵表示 = [(x,x), (x,x), (.,.)]
为每一行进行简化:
如果一行均为x 或 a 的任意组合,可留空该行["", "", (.,.)]
如果一行均为. ,可以用一个元素代替["", "", "."]
如果一行均为_ :(条件不符合)
然后再为整体矩阵进行简化:
如果第m行到第n行之间(不含头尾)均为x ,其他行均为. ,则视为 §6.2〈重叠速成版:垂直结构穿过水平结构的直接限制〉 可简化成 m:n(m、n为负数时表示到最后一行的距离)。m、n为0时应省略[:-1]
如果矩阵里面全部元素是x (全部穿过),应直接不写「穿过表达式」(即默认情况)。
将简化后的穿过矩阵,每行的元素直接连写,行和行之间用逗号 , 连接。[:-1] ,则错误地写成 [,,.]
以下给出其他例子供参考:
廴 ⿻[b]㇋乀 :「㇋ 」有两段竖(一个竖,一个撇),「乀 」穿过 b 段(即撇)𤓷 ⿺爪⿻[c]弓z丶 :「弓z (最后一笔是竖折撇)」有三段竖(𠃍的竖,的竖,的撇),「丶 」穿过 c 段(即撇)𦫵 ⿻[bx]⿰𠃑丨 一 :纵向部件的第一笔「𠃑 」有两段竖,「一 」穿过 b 段(即下面的竖);向部件的第二笔「丨 」直接穿过「一 」身 ⿱丿⿹⿴⿻[.x]冂丿 二一 :「冂 」有一个竖、一个竖钩,「丿 」在竖的下面(.)通过、然后穿过竖钩(x)𠥻 ⿻[,._]〢二t :「〢 」穿过第一横(扩展语法是空行);「〢 」的第一竖垂直触碰(丄形)下面的提(.)、然后下面的提从左边触碰(┤形)第二竖(_)𠂀 ⿴⿻[,.x]〢二 丶 𠕋 ⿻[_xx_,]𦉫T二 :𦉫T 为右下角带勾
6.4. 重叠完整版:反向矩阵结构
EBNF 语法定义:
Overlap_Modifier ::= "[" Overlap_Matrix ("|" Overlap_Matrix)? "]"
以上描述只能表示一个纵向部件和一个横向部件之间的穿插关系,但有些汉字的结构比较复杂,纵向部件里面也有水平笔画 与 横向部件里面的竖直笔画 交叉,因此也需要将反向的纵横穿插关系表示出来。§6.1〈重叠标记的简介及基础概念〉 中提到:
⿻字₁字₂ 中,字₁ 是纵向部件,字₂ 是横向部件。⿻字₁字₂ 中,字₁ 是横向部件 ,字₂ 是纵向部件 。
首先完成一遍§6.3〈重叠完整版:任意穿插的矩阵结构〉 得到「穿过表达式」矩阵字串 "fr,on,t",然后将字₁ 、字₂ 的定义反过来,重复 §6.3〈重叠完整版:任意穿插的矩阵结构〉 得到「穿过表达式」矩阵字串 "ba,ck"。最后将两个字串使用竖线 | 合并,得到最终的重叠完整版的「穿过表达式」 [fr,on,t|ba,ck],其中竖线 | 分隔了正向矩阵结构和反向矩阵结构。
例:「𫠣」(U+2B823) 的 lv0 IDS 条目简化两轮如下:
⿻[1:|b]𠃌⿱⿻𠃊.一. 八d
↓
⿻[1:|b]𠃌⿱
↓
⿻[1:|b]𠃌
「𫠣」的 IDS 条目两轮简化
可见「穿过表达式」表示有前后两个矩阵字串:
正向矩阵字串:1: 。先分析结构:
纵向部件:𠃌 ,横折钩的竖
横向部件: ,横1是「一」,横2是竖折的横
然后判读:横折钩的竖应该在 的横1下面,横2上面。
反向矩阵字串:b 。先分析结构:
纵向部件: ,竖折的竖,被横1分成两段 a 和 b
横向部件:𠃌 ,横折钩的横
然后判读: 竖折的竖 b 段应该和𠃌 的横交叉。
就可完整代表
以下给出另一个虚拟例子供参考:
6.5. 重叠特例:任意穿插曲线笔画(???)
最后看重叠的一个特例「𢀓」(U+22013) :
𢀓 ⿻[r,r,l,l] 工.#(◝◞-◜-◟)
其中#(◝◞-◜-◟) 已知表示一个特殊的连贯曲线笔画,但是因为其特殊的形状和结构无法判断其横向部件(位于 ⿻字₁字₂ 里的 字₂ ),因此这里方括号 [ ] 里面表示的不是矩阵穿过关系,而是单纯这个线段每个 Q 部分是在纵向部件的左边 l 还是右边 r。目前已知的特例只有这一个汉字。
6.6. 全包围、半包围部件的定位
EBNF 语法定义:
IDS_Sequence ::= ... | IDS_BinaryAmbiguousOperator Index_Modifier IDS_Component IDS_Component | ...
Index_Modifier ::= "[" Number "]"
IDS_BinaryAmbiguousOperator ::= [⿴⿵⿶⿷⿼] | ...
除了重叠 IDC 会有歧义,全包围及半包围 IDC 也会产生类似的歧义。
包围方式
IDC 字符
Unicode
全包围
⿴
U+2FF4
半包围
⿵
U+2FF5
⿶
U+2FF6
⿷
U+2FF7
⿼
U+2FFC
产生的什么歧义呢?以一个虚拟的 IDS 举例:「⿴日丶 」。请问这个点应该放在上面的格内还是下面的格内?对于这种歧义情况,白式 IDS 的包围扩展语法为在包围 IDC 后面添加方括号 [ ],里面填写数字使之成为 ⿴[x]字₁字₂ 。其中的 x 是一个正整数,表示字₂ 放置在字₁ (即「日」)的第 x + 1 个四方形全封闭 空间内(从上到下、先中间,然后左到右数)。如果 x 为 0(表示放在第一个全封闭空间)时,整个扩展语法 [0] 可以省略不写。
全包围的「四方形全封闭」空间计数例子:
全包围例子:
𫡆 ⿴[1]⿴ 㠯一一 :「㠯 」共有两个全封闭空间,下划线的 IDS 将「一 」填充在「㠯 」上面的格内,外面的 [1] IDS则将「一 」填充在「㠯 」下面的格内。𢧟 ⿹戈⿴[2]⿴[1]⿴ ⿻[1:]丨#(𠃍-一𠃑-一丿) 丶丶丶
对于半包围 IDS 同理,只是查看的是符合半包围 IDC 包围方式的半封闭空间数量。比如「⿵⺵丶 」的半包围 IDC 是「⿵」,包围方式是「上左右包围」(形似「冂」),因此能得知「⺵」共有 3 个「⿵」空间,从左到右分别是 [0](默认省略)、[1] 和 [2]。
半包围例子:
𦥮 ⿻⿷[1] #(-一𠃑-一丨) 一⿼[1] #(一-𠃑一-𠃍) 一(T)
6.7. 减法消歧义
EBNF 语法定义:
IDS_Sequence ::= ... | IDS_BinaryAmbiguousOperator Index_Modifier IDS_Component IDS_Component | ...
IDS_BinaryAmbiguousOperator ::= ... | [㇯]
最后加上一个可在字统网快速使用的消歧义:当使用减法「㇯」这个二元 IDS 符号时(如㇯字₁字₂ ),表示从字₁ 的结构中去掉字₂ 后剩下的部分;但是由于字₁ 里面可能有多个字₂ 部件,因此可以在「㇯」IDS 后面加上方括号 [ ] 来指定要去掉的字₂ 是第几个(从左到右、上到下数,起始为 0)。如果[ ] 里面的数字为 0,则表示去掉第一个字₂ ,此时 [0] 可以省略不写。
例子(可用字统网查询):
IDS
汉字
说明
㇯王一 土
「王」去掉第0个「一」,即上面的「一」
㇯[1]王一 工
「王」去掉第1个「一」,即中间的「一」
㇯[2]王一 干
「王」去掉第2个「一」,即下面的「一」
㇯品口 吅
「品」去掉第0个「口」,即上面的「口」
㇯[1]品口 吕
「品」去掉第1个「口」,即下左的「口」
注意事项:
减法 IDS 并不会用在 IDS 数据库内,仅用于快速在字统网查询汉字。
进行减法操作时,字₁ 里由「笔画链」 组成的部件不可被计数、删除。例:㇯[1]日一 是非法语句,因为「日」的外壳是「口」,而「口」是由「笔画链」所组成的(#(-丨𠃍-一z) ),因此「口」里面的横不可被删除;但是㇯日一 可得「口」。
7. 唯一化及统一化
7.1. lv0 的唯一化
EBNF 语法定义:
IDS_Locale_Sequence ::= Unique_Sequence_Separator? IDS_Sequence ...
Unique_Sequence_Separator ::= "{" ("?" One_Digit_Number?)? Ideograph_Char_with_Variant Unicode_Sources? "}"
虽然以上定义了诸多延展格式,但是仍会有部分形似汉字无法仅透过 IDS 区分。这种情况下,为了保证每个 IDS 组合都可以反向唯一地映射到一个汉字,在 IDS 组合前面插入带有「抽象构型」的「唯一化分隔符」(EBNF 里面的 Unique_Sequence_Separator)来实现。
「唯一化分隔符」的语法为:{,汉字,},如:{字},其中的汉字必须是符合这个 IDS 组合汉字的「抽象构型」。以下是判断「唯一化分隔符」的使用原则:
「唯一化分隔符」不会添加在较常用字,而是添加在较生僻字;
和中日韩笔画区段 (CJK Strokes) 有一样笔画链的汉字会添加「唯一化分隔符」。
汉字的前后还可以添加一些额外的标识来提供更多信息和区分:
与同字其他提交源有较大差异、且与另外码位撞形的 IDS 条目也会添加「唯一化分隔符」。此时在「与同字其他提交源有较大差异」的汉字前面加上问号(和一位数字?)即 {?,数字?,汉字,},如:{?字}、{?0字};
如果该 IDS 组合是针对特定提交源的,可在汉字后面加上提交源的「字形变体标识符」(参考 §4.3.1〈提交源的变体〉 )即 {,汉字,大写字母,},如:{字T} 代表 T 源。
例子:
「日」和「曰」的 IDS 完全一样:⿴囗一 。为了区分它们,判断常用字是「日」,然后给「曰」使用「唯一化分隔符」:{曰}⿴囗一 。
「土」和「士」的 IDS 完全一样:⿱十一 。为了区分它们,判断常用字是「土」,然后给「士」使用「唯一化分隔符」:{士}⿱十一 。
「一」的 IDS lv0 条目里面有两个形:一 #(H)(.);{一}#(T)(t) ,其中「一t 」的笔画链#(T) 与「㇀ 」(U+31C0,提) 完全一样,因此需要使用「唯一化分隔符」来区分「一t 」的 IDS。
「叱(U+53F1) 」有两个形:⿰口.𠤎.(.) (撇𠤎)和⿰口.七.(V) (横七)。其中「叱V 」来源和已编码字「𠮟(U+20B9F) 」撞形,因此需要使用「唯一化分隔符」来区分「叱V 」的 IDS:{?叱}⿰口.七.(V) 。
「𡮂(U+21B82) 」有两个形:{𡮂J}⿱小.𤽄V(J) J 源与{𡮂T}⿱小s𤽄V(T) T 源。这两者的表达式和「𡭽(U+21B7D) 」的 IDS 组合一样:⿱小s𤽄V(.);⿱小.𤽄V(J) ,因此给「𡮂(U+21B82)」的 IDS 组合「唯一化分隔符」加上按提交源的「字形变体标识符」。
(主要原因是「𡮂(U+21B82)」如果写成⿱少𣌢 ,按照「白式 IDS 简化」后还是会变成⿱小𤽄 ……这部分目前没有公开资料可参考,仅由字统网站长白易口头说明。)
「抽象构型」(abstract shape) 指的是汉字可以拥有不同的变体部件,但仍可辨识和区分汉字的意义。详细可参考 https://zhuanlan.zhihu.com/p/480635382 。例如:「土 」和「士 」的「抽象构型」并不一样,因为笔画长短影响了汉字的定义和识别;但是「天 」和「天 」的「抽象构型」是一样的,因为笔画长短不影响 汉字的定义和识别,仍被阅读者认定为同一个汉字。因此在 IDS 组合中,引用「抽象构型」就一定 可以区分 IDS 一样但含义不同的汉字了。
7.2. lv1 的合并
在 ids_lv1(即字统网使用的)中,所有的笔画级别差异(即相同位置的相似笔画,如在同一位置上的「丶 」和「乀 」)都将被合并。例:「𡕆 」(U+21546) 有两个
IDS:⿰壴t咨.(.);⿰壴t咨T(T) 。其中的「.」和「T」只是将「咨 」中「次 」的「冫 」的点的方向改变了。因此,「.」和「T」都只造成了笔画级别差异。所以这两个 IDS 会在 ids_lv1 中被合并为「⿰壴咨(.,T) 」。
合并的过程主要是通过移除附着在汉字部件后面、没有括号、修饰笔画样式的「字形变体标识符」(见 §4.3.3〈笔画样式及位置差异的变体〉 )。合并的笔画类「字形变体标识符」有以下几种:
合并的笔画避让
例子
「㇐」(横)变「㇀」(提,t)
一. (横)和 一t (提)土. 和 土t 马. 和 马t (「驮」左)里. 和 里t (「野」左)血. 和 血t (「衅」左)金. 和 金dt (「釒」下)
「㇏」(捺)变「丶」(点,d)
人. 和 人d 大. 和 大d 又. 和 又d 金. 和 金d. (「趛」H源右上)辰. 和 辰d (「辱」上)
「乚」(竖弯钩)变「㇙」(竖提,t)
儿. 和 儿t (「頹」左下)电. 和 电t (「鵪」左下)厄. 和 厄d (「顾」左)己. 和 己t (「改」左)九. 和 九t (「鸠」左)
「丨」(竖)变「丿」(撇,p)
半. 和 半p (「判」左)干. 和 干p (「幵」左)丰. 和 丰..p (「」,「邦」左)
7.3. lv2 的合并
在 ids_lv2 中,IDS 组合内的汉字部件将尽量替换成靠近 G 源常用字的形态;UCV 列表中被认为「必须统一」的部件也会被合并。例如:lv1 的伔 ⿰亻冗(.);⿰亻⿱冖儿(J) 在 lv2 中会被合并为伔 ⿰亻冗(.,J) ,因为「冗」的「⿱冖几 」「⿱冖儿 」字形差异在 UCV #119 中被认为「必须统一」,因此合并了「字形变体标识符」. 和 J。
7.4. 目标
以上所有的唯一化和统一化规则的目标都是为了让每个 IDS 组合都能唯一地映射到一个【汉字+「字形变体标识符」】,并且反向的【汉字+「字形变体标识符」】也能唯一地映射到 IDS 组合(不包括§4.3.1 里的另类定义组),以便于机器能够唯一化地验证和处理。下表展示本页所使用的白式 IDS 组合经过 lv0 唯一化后的数据,注意每栏里面不会有重复的内容。
本页所使用的白式 IDS 组合 lv0 数据表(展开阅读)
汉字+「字形变体标识符」
IDS 组合
令.
⿱亽龴.
令H
⿱亼.龴.
令J
⿱人.𪜁
令d..
⿳人d丶.龴.
令dh.
⿱亼d龴.
令dhs
⿱人d𪜁
令hdx
⿱亽卩
令hsx
⿱亼.卩
冷.
⿰冫令.
冷H
⿰冫令H
冷J
⿰冫令J
刢.
⿰令d..刂
刢J
⿰令dhs刂
刢T
⿰令dh.刂
父.
⿱八d乂.
父qq222
⿱儿.乂.
.
⿱夂.月.
.
⿱攵.⺼.
母
⿻⿴#(-𠃌𠃊x0)⺀一
又.
#(-乀x1㇇)
𡆢
⿴囗#(◞x3◟◜◝-◟)
甴
⿻[:-2]丨日
由
⿻[:-1]丨日
申
⿻丨日
甲
⿻[1:]丨日
曱
⿻[:2]丨日
田
⿴囗.十.
曲
⿻[:-1]〢日
𫠣
⿻[1:|b]𠃌⿱⿻𠃊.一.八d
𫡆
⿴[1]⿴㠯.一.一.
日
⿴囗.一.
曰
{曰}⿴囗.一.
土.
⿱十.一.
土t
⿱十.一t
士.
{士}⿱十.一.
士t
{士}⿱十.一t
叱.
⿰口.𠤎.
叱V
{?叱}⿰口.七.
𡭽. (U+21B7D)
⿱小s𤽄V
𡮂J (U+21B7D)
⿱小.𤽄V
𡮂J (U+21B82)
{𡮂J}⿱小.𤽄V
𡮂T (U+21B82)
{𡮂T}⿱小s𤽄V
子.
⿻了.一.
子t
⿻了.一t
孑
⿻了.㇀
一.
#(H)
一t
{一}#(T)
㇀
#(T)
⺄
#(HNg)
㇁
#(Wg)
〇
#(◟◜◝◞z)
口.
#(-丨𠃍-一z)
𠂆.
#(丿丿)
𠃎
#(一-丨)
弓
#(𠃍-一㇉)
己
#(𠃍-一乚)
巳
#(一-𠃍乚)
8. 实操练习
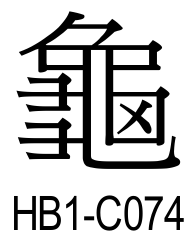
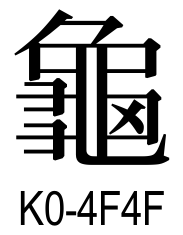
接下来请尝试理解「龜」(U+9F9C) 的白式 IDS 条目(lv0),并依据 IDS 绘出最终字形。【注:在编撰时的 IDS 数据库 里面,⿴[4]?乂 错误写成⿴[3]?乂 ,本页面暂时将其调整以符合预期字形。】
龜 ⿱丿⿻#(-丨一-𠃍丨b一b乚)⿰⿱⺕⺕⿼コ乂d(.);⿱⺈⿹⿴⿻[1:]⿺乚.#(丨b一-𠃍)#(一-𠃍丨b一)乂d⿱⺕⺕(H);⿱⺈⿴[4]⿻[.,.__,r,,bxx]⿹⿺乚.丨⿱ココ⿱#(一-𠃍丨b一)コ乂d(J);⿱⺈⿻[1:]⿺乚.丨⿱#(一-𠃍丨b一)⿰⿱⺕⺕⿼コ乂d(K);⿱⺈⿴[4]⿻[.,.__,r,,bx.]⿹⿺乚.丨⿱ココ⿱#(一-𠃍丨b一)コ乂d(T);⿱⺈⿻#(-丨一-𠃍丨b一b乚)⿰⿱⺕⺕⿼コ乂d(V);⿱⺈⿻[1:]乚.⿱口.⿰⿱⺕⺕目(q4072)
将 IDS 依据「字形变体标识符」拆分得到 IDS 表:
变体标识符 ID
IDS 条目
参考示例字形
(.)
⿱丿⿻#(-丨一-𠃍丨b一b乚)⿰⿱⺕⺕⿼コ乂d
(H)
⿱⺈⿹⿴⿻[1:]⿺乚.#(丨b一-𠃍)#(一-𠃍丨b一)乂d⿱⺕⺕
(J)
⿱⺈⿴[4]⿻[.,.__,r,,bxx]⿹⿺乚.丨⿱ココ⿱#(一-𠃍丨b一)コ乂d
(K)
⿱⺈⿻[1:]⿺乚.丨⿱#(一-𠃍丨b一)⿰⿱⺕⺕⿼コ乂d
(T)
⿱⺈⿴[4]⿻[.,.__,r,,bx.]⿹⿺乚.丨⿱ココ⿱#(一-𠃍丨b一)コ乂d
(V)
⿱⺈⿻#(-丨一-𠃍丨b一b乚)⿰⿱⺕⺕⿼コ乂d
(q4072)
⿱⺈⿻[1:]乚.⿱口.⿰⿱⺕⺕目
组装验证(展开阅读)
ID
组装
(.)
(H)
(J)
(K)
(T)
(V)
(q4072)
9. 完整 EBNF 语法定义
下面是白式 IDS 语法的 EBNF(扩展巴科斯-瑙尔范式)定义。以下定义由 @NightFurySL2001 整理且仅供参考,并非正式定义。以下使用 W3C XML 的 EBNF 语法表述。
/* zi.tools IDS Database EBNF syntax */
IDS_Definition_Row ::= Ideograph_Char TAB IDS_Locale_Definition (TAB IDS_Alternative_Definition)
/* 单个部件描述 */
IDS_Locale_Definition ::= IDS_Sequence | IDS_Locale_Sequence (";" IDS_Locale_Sequence)*
IDS_Alternative_Definition ::= (IDS_Sequence | IDS_Locale_Sequence) (";" (IDS_Sequence | IDS_Locale_Sequence))*
IDS_Locale_Sequence ::= Unique_Sequence_Separator? IDS_Sequence Variant_Identifier_Definition?
IDS_Sequence ::= Stroke_Chain
| IDS_UnaryOperator IDS_Component
| IDS_BinaryOperator IDS_Component IDS_Component
| IDS_BinaryOverlapOperator Overlap_Modifier IDS_Component IDS_Component
| IDS_BinaryAmbiguousOperator Index_Modifier IDS_Component IDS_Component
| IDS_TrinaryOperator IDS_Component IDS_Component IDS_Component
IDS_Component ::= IDS_Sequence | Stroke_Chain | Ideo_with_Variant_ID | Curves | [リ〢〣コ]
/* 4. 汉字的字形变体 */
Ideo_with_Variant_ID ::= Ideograph_Char_with_Variant Variant_Identifier?
Variant_Identifier_Definition ::= "(" Variant_Identifier ("," Variant_Identifier)* ")"
Variant_Identifier ::= Wildcard_Source | Unicode_Sources | UCV_Full_Position | Imaginary_UCV | Alternate_Variants
Wildcard_Source ::= "."
Unicode_Sources ::= [BGHJKMPSTUVQ]
UCV_Full_Position ::= [qpxy] UCV_ID_Number UCV_Position_Number
UCV_ID_Number ::= Three_Digit_Number [a-z]?
UCV_Position_Number ::= (Positive_Numeral | Two_Digit_Number) [xy]?
Imaginary_UCV ::= "qq" UCV_ID_Number+
Alternate_Variants ::= [0-9a-z.]+
/* 5. 笔画之间的相接 */
Stroke_Chain ::= "#" "(" Stroke_Part+ "z"? ")"
Stroke_Part ::= StReversed_Indicator? (Ideograph_Char | Stroke_Letter) (StCrossing_Indicator | StBreak_Indicator)?
Stroke_Letter ::= [HSPN] [g]? | [SP] "Hw" [g]? | [DTJZ] | "Wg" | [Q][abcd]
StReversed_Indicator ::= "-"
StCrossing_Indicator ::= "x" Number
StBreak_Indicator ::= "b"
/* 6. 部件之间的重叠穿插 */
Overlap_Modifier ::= "[" Overlap_Matrix ("|" Overlap_Matrix)? "]"
Overlap_Matrix ::= Overlap_Horizontal_Indexing | Overlap_Rows | Overlap_Cell+
Overlap_Horizontal_Indexing ::= (Number | Negative_Number)? ":" (Number | Negative_Number)?
Overlap_Rows ::= Overlap_Row? ("," Overlap_Row?)+
Overlap_Row ::= Overlap_Cell*
Overlap_Cell ::= Overlap_Identity | Overlap_Crossing | Overlap_Non_Crossing
Overlap_Identity ::= "." | "_"
Overlap_Crossing ::= [xabcd]
Overlap_Non_Crossing ::= [lr]
Index_Modifier ::= "[" Number "]"
/* 7. 统一化 */
Unique_Sequence_Separator ::= "{" ("?" One_Digit_Number?)? Ideograph_Char_with_Variant Unicode_Sources? "}"
/* 字符定义 */
Ideograph_Char ::= Ideograph_Char_with_Variant | Curves | [リ〢〣コ]
Ideograph_Char_with_Variant ::= Hanzi | CJK_Stroke | [ユス]
Hanzi ::= \p{Ideographic=Y} | \p{Radical=Y} |
Curves ::= [◝◞◟◜]
CJK_Stroke ::= [#x31C0-#x31E3] // U+30E4 和 U+30E5 未收录进 zi.tools 笔画库
TAB ::= #x0009
IDS_UnaryOperator ::= [⿾⿿]
IDS_BinaryOperator ::= IDS_BinaryUnique | IDS_BinaryOverlap | IDS_BinaryAmbiguousWrapping
IDS_BinaryUniqueOperator ::= [⿰⿱⿸⿹⿺⿽]
IDS_BinaryOverlapOperator ::= "⿻"
IDS_BinaryAmbiguousOperator ::= [⿴⿵⿶⿷⿼㇯]
IDS_TrinaryOperator ::= [⿲⿳]
Positive_Numeral ::= [1-9]
One_Digit_Number ::= "0" | Positive_Numeral
Two_Digit_Number ::= One_Digit_Number One_Digit_Number
Three_Digit_Number ::= One_Digit_Number One_Digit_Number One_Digit_Number
Number ::= "0" | Positive_Numeral One_Digit_Number*
Negative_Number ::= "-" Positive_Numeral One_Digit_Number*
上面的 EBNF 定义也被转换成使用 Python regex 模块的正则表达式实现。你可以对「白式 IDS 数据库」内的 .txt 文件运行该 Python 脚本文件 以验证该 EBNF 定义是否对应「白式 IDS 数据库」的条目。




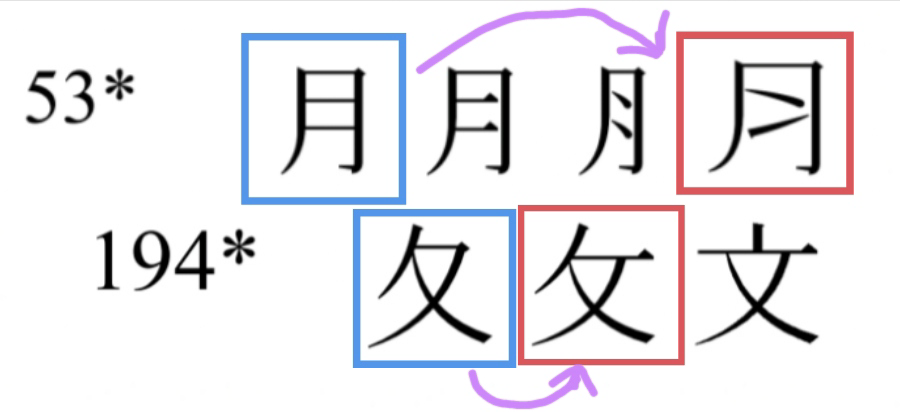


 ,而不是
,而不是